DINO(Facebook)
이번 논문은 Emerging Properties in Self-Supervised Vision Transformers (Facebook AI Research Explained)입니다.
논문을 이해하지 못하고 YouTube의 영상을 보고 소개합니다. ViT(Vision Transformer)로 Self-Supervised 학습입니다. 학습 방법으로 Facebook에서 만든 DINO방식인데요. 일단 Self-Supervised의 장점은 raw-data에서 유효한 특징을 얻어내는 것 입니다. 그냥 사진을 가지고 강아지 배 고양이를
우리가 따로 박스를 치거나 segmentation을 안해도 됩니다.
Vit에 대해서 저도 잘 몰라 링크를 걸겠습니다.
그냥 대강 제가 이해한 것은 사진의 구역을 일정크기로 나누고 이것을 임베딩레이어를 통과시켜 트랜스포머에 넣는 것 입니다.
제가 집중한 것은 Vit와 같이 NLP에서 혁신이라 불린 트랜스포머를 CV에 적용한 것 보다, 과연 raw데이터만으로 라벨링을 할 수 있을 정도인가 입니다.
그래서 ImageNet data로 pretrain된 것을 진행중인 프로젝트 데이터에 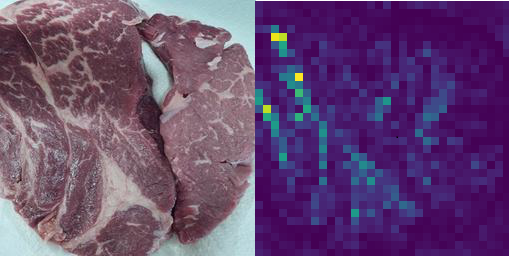 한번도 우리의 데이터를 훈련하지 않았는데도 고기의 지방을 특정지어냈습니다.
한번도 우리의 데이터를 훈련하지 않았는데도 고기의 지방을 특정지어냈습니다.
프로젝트를 진행하며 고려 했던 segmentation 된 이미지를 함께 모델에 넣어 더욱 성능향상을 노릴 것 인가에 대해서
segmentation용으로 사용해볼만 하다고 느꼈지만 grad-CAM에서 확인하였을 때 지방보다 지방을 제외한 것을 더 중요하게 보고
성능 또한 나쁘지 않아 시도하지는 않았습니다.
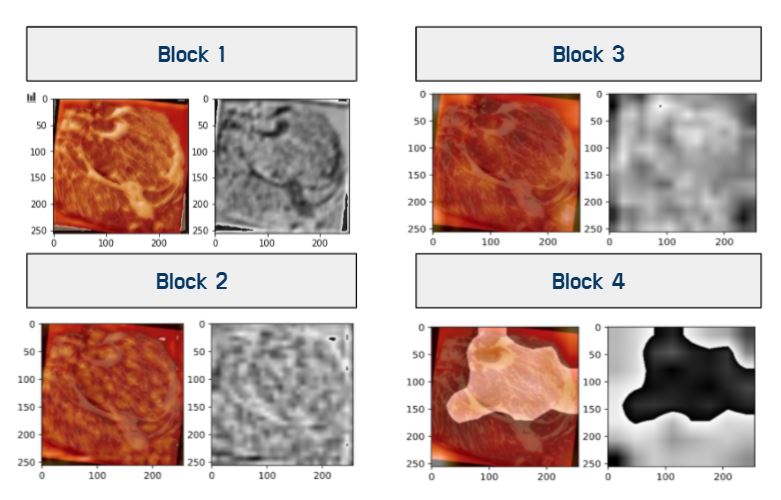
하지만 나중에 데이터가 raw-data만 있고 segmentation이 필요하거나 다른 labeling이 필요하다고 한다면 충분히 활용해 보고 싶습니다.